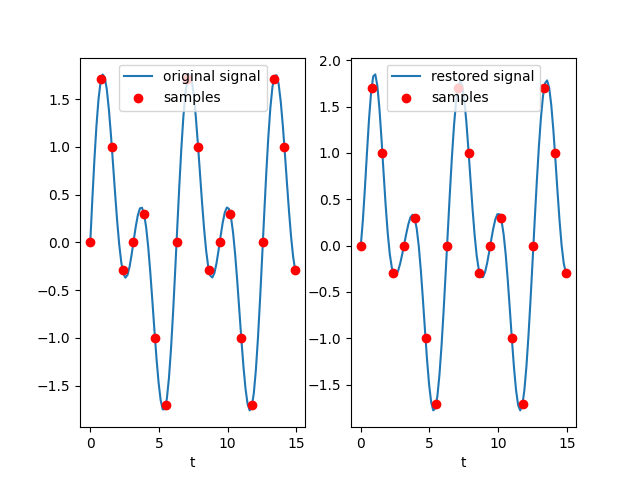
根据香农采样定理可知,采样频率不小于连续信号频谱中最高频率2倍的离散信号,可以使用香农插值公式不失真的还原成连续信号。
插值公式如下:
$
f(t)=\sum_{n=-\infty}^{+\infty}f[n]sinc(\dfrac{t-nM}{M})
$
其中,$f[n]$表示第$n$个采样点的值,M表示采样间隔。
代码如下:
1 | import numpy as np |
根据香农采样定理可知,采样频率不小于连续信号频谱中最高频率2倍的离散信号,可以使用香农插值公式不失真的还原成连续信号。
插值公式如下:
$
f(t)=\sum_{n=-\infty}^{+\infty}f[n]sinc(\dfrac{t-nM}{M})
$
其中,$f[n]$表示第$n$个采样点的值,M表示采样间隔。
代码如下:
1 | import numpy as np |
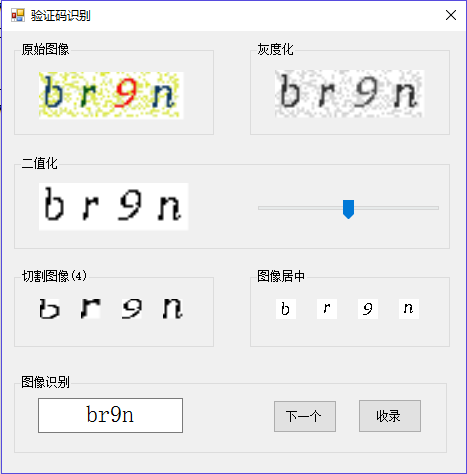
yolact是一个实时的实例分割算法,是目前分割速度最快的算法,而且生成mask的质量也很高。论文上说该算法还可以做目标检查,而且速度和准确度都能够达到(接近)YOLOv3的水平,于是就尝试了一下。将算法该成Paddle上的代码后,训练到5000多个step的时候,conf_loss突然就变成了nan。
以前遇到nan的问题都是因为学习率过大,而且是在训练初期发生的。我这里的学习率用的是0.001,应该不是学习率的问题,排除。
由于采用的是动态图编写的代码,因此可以通过一步一步的跟踪代码,来诊断错误。从loss一步步向上查找问题,发现target_logits中存在非常小的数据(负数),如下面的图:
loss代码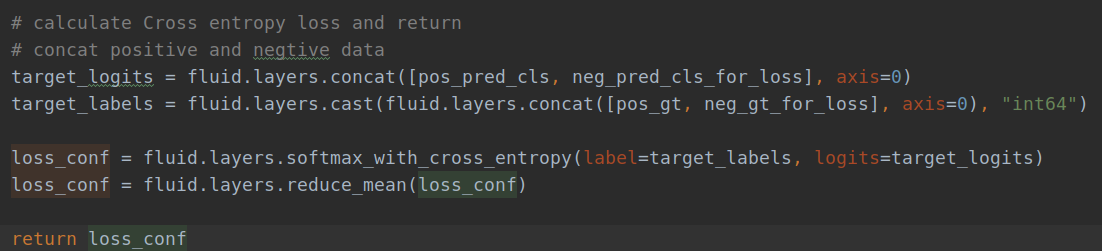
target_logits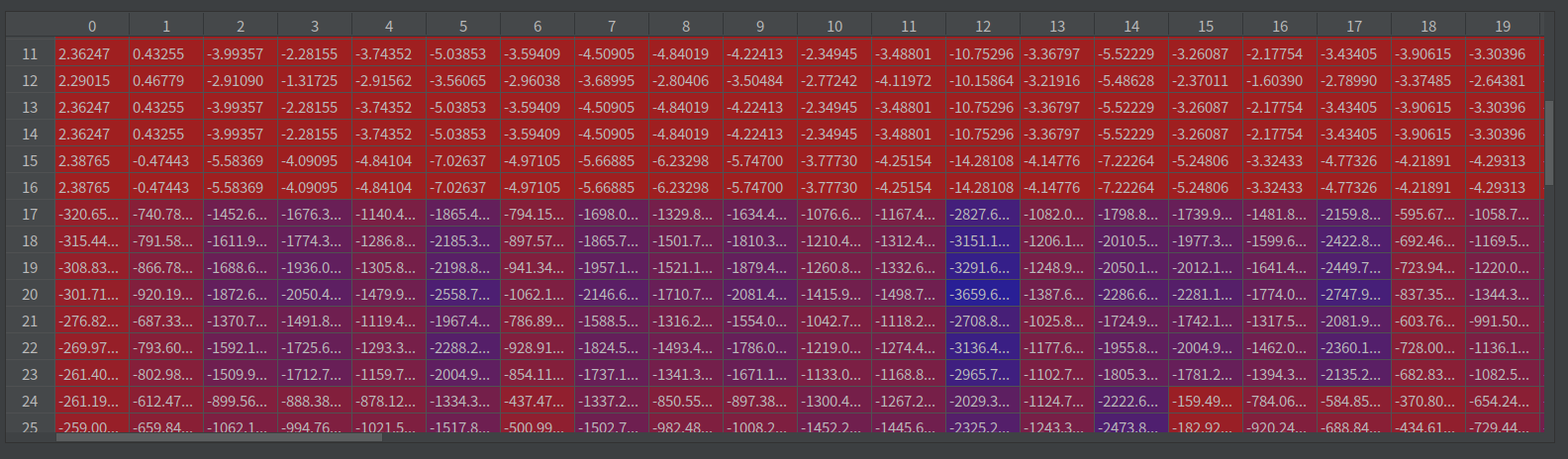
target_labels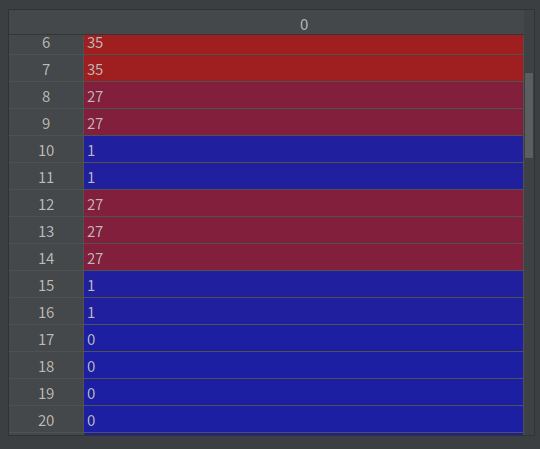
conf_loss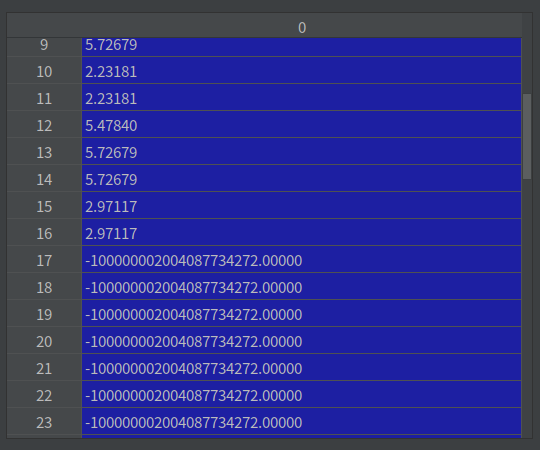
这个问题是由于logits太负了,导致其指数接近与0引起的。因此,首先想到的就是对logits进行裁剪,裁剪到[-10,10]之间,解决了这个问题。
注:对于
log函数,如何参数是一个负数,结果中就会出现nan,而如果参数是0,结果中就会出现inf。
不过后来训练时又出现了其他nan的问题,详细观察训练记录发现,损失会出现突然变大的情况,怀疑是异常样本引起的。于是,便记录最近100个损失,如果当前的损失大于这100个的平均值的10倍,则认为是异常数据,不训练该数据。
从pip安装的OpenCV居然无法显示菜单栏的图标,实在无法忍受,各种查资料找到了解决方法,只需卸载OpenCV,然后从conda中安装即可。
1 | pip uninstall opencv-python |
最近在学习3D相关的算法,遇到SMPL算法,不甚理解,所以打算自己实现一遍,毕竟————学习新知识的最好方法就是自己实现一下。
项目地址:https://github.com/killf/smpl
model.py是加载模型文件和算法的入口。
1 | import numpy as np |
传统的目标检测(R-CNN、Fast R-CNN、Faster R-CNN)都是从提取候选框开始的,本文介绍两种提取候选框的方法。
selectivesearch是一个用Python编写的提取候选框的方法,基于skimage,项目地址:https://github.com/AlpacaDB/selectivesearch。
首先,使用pip安装selectivesearch:
1 | pip install selectivesearch |
然后,使用如下代码提取并查看候选框:
1 | import selectivesearch.selectivesearch as ss |
随机姿态的SMPLX模型可能千奇百怪,想生成一个随机的
真实人体需要包含一些人体先验知识。human_body_prior(VPoser)是一个变分自编码器,用于将人体姿态嵌入到隐空间,也可以将隐空间里的随机向量,映射为一个真实存在的姿态。
项目地址:https://github.com/nghorbani/human_body_prior
使用pip从github中进行安装,pypi中的版本比较老,而且官方版本在window平台下有一些问题。
1 | pip install git+https://github.com/killf/human_body_prior.git |
要想直接使用VPoser,还需要从官网下载训练好的模型,代码如下:
1 | from human_body_prior.tools.model_loader import load_model |
将pose参数转换为3D模型:
1 | import smplx |
相比于静态图,动态图更灵活、易读,特别是在编写条件语句、循环语句时很方便,非常适合算法研究。
本文通过一个简单的Mnist手写数字识别案例,演示TensorFlow2.0中动态图的使用方法。
代码如下:
1 | import tensorflow as tf |
相比于静态图,动态图更灵活、易读,特别是在编写条件语句、循环语句时很方便,非常适合算法研究。
本文通过一个简单的Mnist手写数字识别案例,演示PyTorch中动态图的使用方法。
代码如下:
1 | import os |
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia-plus根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true